Sitemap під контролем: як автоматично знаходити 404, редіректи й noindex у важливих URL
Sitemap часто сприймають як файл, який один раз налаштували в CMS і згадують про нього тільки під час великого SEO-аудиту. Для невеликого сайту це ще може пройти. Але коли на сайті регулярно з'являються категорії, посадкові сторінки, акційні URL і старі матеріали, sitemap треба контролювати як операційний список важливих сторінок.

Проблема не в тому, що sitemap іноді ламається повністю. Частіше він виглядає нормальним, але всередині з'являються тихі поломки: важлива сторінка віддає 404, URL з реклами пішов у редірект, комерційний лендінг випадково отримав noindex, а стара категорія зникла з sitemap після релізу. Якщо такі речі бачать тільки раз на місяць, бізнес втрачає трафік до того, як команда відкриє аудит.
Для базової автоматизації достатньо Google Sheets, Apps Script і кількох правил. Sitemap можна розпарсити через XmlService, URL перевіряти через UrlFetchApp, а результати складати в таблицю через Spreadsheet service. Для SEO-логіки корисно тримати поруч документацію Google про sitemap, noindex і redirects.
Що перевіряти в sitemap-моніторингу
Не треба перетворювати першу версію на повний crawler. Завдання простіше: регулярно перевіряти URL, які вже вважаються важливими, і швидко показувати зміни, що потребують реакції.
Мінімальний набір полів:
| Поле | Для чого потрібне |
|---|---|
url | адреса з sitemap або whitelist |
in_sitemap | чи є URL у поточному sitemap |
http_status | відповідь сторінки |
final_url | куди URL прийшов після редіректу |
canonical | який canonical знайдено в HTML |
index_rule | index, noindex або unknown |
priority | бізнес-важливість URL |
last_checked | коли була остання перевірка |
action | що робити з інцидентом |

Такий формат дає не просто список помилок, а робочу чергу. Команда бачить, що саме сталося: сторінка недоступна, змінився final URL, з'явився noindex, canonical вказує не туди або URL більше не присутній у sitemap.
Не всі URL однаково важливі
Якщо перевіряти весь sitemap однаково, таблиця швидко стане шумною. У великому sitemap можуть бути тисячі URL, але бізнес-ризик у них різний. Випадковий 404 у старій новині і 404 на посадковій сторінці з paid traffic не мають однакової ваги.
Практична шкала priority:
| Priority | Приклади URL | Реакція |
|---|---|---|
critical | комерційні лендінги, категорії, сторінки кампаній | alert одразу |
high | трафікові статті, evergreen-матеріали, сторінки з лідами | перевірити в той самий день |
normal | звичайні blog posts і другорядні сторінки | додати в план робіт |
low | архівні або службові URL | дивитися тільки при масовій проблемі |
Окремо варто тримати whitelist money pages. Sitemap може змінитися через CMS, плагін або реліз, але список критичних URL повинен жити незалежно. Якщо сторінка з whitelist зникла з sitemap, це вже сигнал, навіть якщо сама сторінка ще відкривається.
Архітектура перевірки
Базова схема виглядає так:
Sitemap XML -> Apps Script parser -> URL checks -> Google Sheets -> alert queue
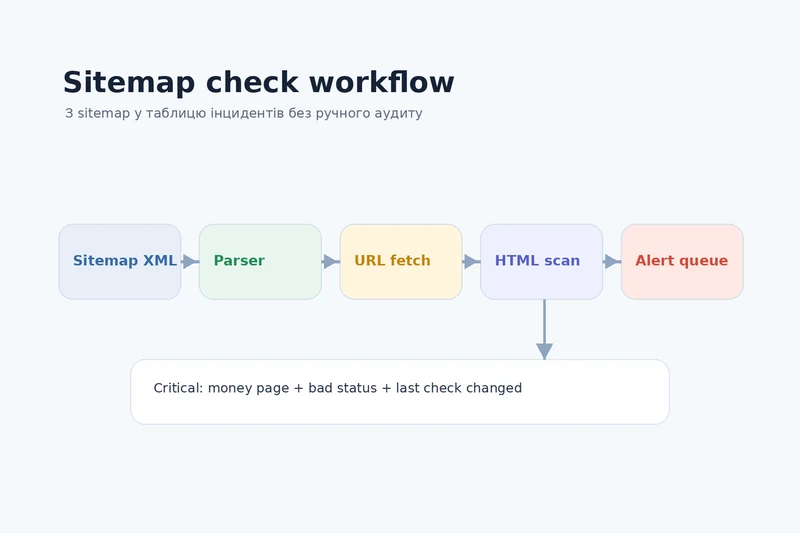
Спочатку Apps Script забирає sitemap XML і витягує URL. Потім об'єднує цей список із whitelist. Далі для кожного URL робиться HTTP-перевірка, фіксується status code, final URL і базові індексні сигнали в HTML. Результат потрапляє в таблицю, де вже працює простий status engine: ok, warning, critical.
Головне правило: alert має створюватися тільки тоді, коли змінився стан або коли інцидент ще не закритий. Якщо сторінка вже три дні має 404 і команда про це знає, не треба щоранку створювати нову паніку. Краще оновлювати last_seen і тримати один відкритий інцидент.
Базовий приклад Apps Script
Нижче не готовий production crawler, а робочий каркас. Він показує логіку: взяти sitemap, пройтися по URL, перевірити status і знайти noindex у HTML.
function checkSitemapUrls() {
const ss = SpreadsheetApp.getActive();
const sheet = ss.getSheetByName('Url_Monitor');
const sitemapUrl = 'https://example.com/sitemap.xml';
const sitemapXml = UrlFetchApp.fetch(sitemapUrl, {
muteHttpExceptions: true
}).getContentText();
const urls = parseSitemapUrls_(sitemapXml).slice(0, 100);
const now = new Date();
const output = [['url', 'http_status', 'final_url', 'index_rule', 'last_checked', 'action']];
urls.forEach(url => {
const result = checkUrl_(url);
output.push([
url,
result.status,
result.finalUrl,
result.indexRule,
now,
result.action
]);
});
sheet.clearContents();
sheet.getRange(1, 1, output.length, output[0].length).setValues(output);
}
function parseSitemapUrls_(xml) {
const doc = XmlService.parse(xml);
const root = doc.getRootElement();
const ns = root.getNamespace();
return root
.getChildren('url', ns)
.map(item => item.getChildText('loc', ns))
.filter(Boolean);
}
function checkUrl_(url) {
const response = UrlFetchApp.fetch(url, {
followRedirects: false,
muteHttpExceptions: true
});
const status = response.getResponseCode();
const headers = response.getAllHeaders();
const location = headers.Location || headers.location || '';
const html = String(response.getContentText() || '').slice(0, 120000);
const hasNoindex = /<meta[^>]+name=["']robots["'][^>]+noindex/i.test(html) ||
/<meta[^>]+content=["'][^"']*noindex/i.test(html);
let action = 'none';
if (status >= 400) action = 'restore page or remove from sitemap';
else if (status >= 300 && status < 400) action = 'check redirect target';
else if (hasNoindex) action = 'remove noindex or exclude URL';
return {
status,
finalUrl: location || url,
indexRule: hasNoindex ? 'noindex' : 'index',
action
};
}У реальному проєкті варто додати обробку sitemap index, batch-перевірки, повторні спроби для тимчасових помилок і окрему вкладку для whitelist. Але навіть така версія вже ловить головне: сторінка перестала відкриватися, почала редіректити або стала неіндексованою.
Обмеження Apps Script
Apps Script зручний для старту, але не треба робити з нього великий crawler. У UrlFetchApp є квоти, час виконання скрипта обмежений, а великі sitemap можуть містити десятки тисяч URL. Тому перша стабільна версія має працювати батчами:
- перевіряти не весь sitemap за один запуск;
- окремо контролювати
criticalіhighURL; - зберігати курсор останньої перевірки;
- використовувати
fetchAllтільки там, де зрозумілі ліміти; - не запускати перевірку щохвилини без потреби.
Для великого сайту логіка така: Apps Script відповідає за контрольний шар і таблицю інцидентів, а не за повний технічний crawl. Якщо потрібно обходити сотні тисяч сторінок, краще підключати окремий crawler, API сервісу або серверну задачу.
Як розділяти warning і critical
Найцінніша частина системи не код, а правила статусів. Якщо все позначати як critical, команда швидко перестане реагувати. Краще одразу розділити сигнали.
critical:
- money page віддає 404 або 5xx;
- сторінка з paid traffic отримала
noindex; - важлива категорія зникла з sitemap;
- canonical веде на іншу сторінку без зрозумілої причини.
warning:
- URL редіректить, але final URL відкривається;
lastmodдавно не оновлювався на сторінці, яку часто редагують;- сторінка є у whitelist, але відсутня в sitemap;
- тимчасова 429 або 503 повторюється кілька запусків.
Так команда бачить різницю між “треба лагодити зараз” і “треба перевірити в плановому режимі”.
Перший робочий запуск
Для старту не треба перевіряти весь сайт. Нормальний перший запуск виглядає так:
- Додати 30-100 критичних URL у whitelist.
- Забрати URL із основного sitemap.
- Перевірити status code, redirect і
noindex. - Записати результат у Google Sheets.
- Окремо показати тільки
criticalі новіwarning.
Sitemap-моніторинг корисний саме тому, що він дешевий і регулярний. Він не замінює великий аудит, але закриває сліпу зону між аудитами. Важлива сторінка не повинна тихо випадати з індексації, ламатися після релізу або жити з випадковим noindex до наступної ручної перевірки.
Останні статті

Контент старіє тихо: як у Google Sheets зібрати dashboard сторінок, які треба оновити
Контент рідко старіє різко. Частіше сторінка просто повільно втрачає кліки, CTR, позиції або комерційний сенс. У звітах це не виглядає як аварія: немає 500, немає різког…
Контроль цін конкурентів у Google Sheets: коли простий моніторинг корисніший за складний парсер
Багатьом інтернет-магазинам не потрібен великий price intelligence інструмент на старті. Їм потрібна відповідь на простіші питання: по яких товарах конкурент уже дешевши…

UTM без хаосу: як перевіряти рекламні посилання в Google Sheets до запуску кампанії
UTM-помилки рідко видно в момент запуску кампанії. Реклама вже крутиться, лист уже пішов у базу, партнер уже поставив посилання, а проблема проявляється пізніше: трафік…

Індексація без ручної рутини: як перевіряти нові URL через Search Console API та Google Apps Script
Публікація нової сторінки ще не означає, що вона вже працює в пошуку. На сайті URL може відкриватися, у CMS статус може бути published , у редакційному плані задача може…
Google Sheets + Merchant Center: як автоматично знаходити помилки у фіді до того, як вони вдарять по продажах
Помилки у товарному фіді рідко виглядають драматично в момент, коли вони з'являються. У таблиці просто зник image_link , у частини SKU не оновилася ціна, кілька това…

Search Console під наглядом: як автоматично ловити просідання сторінок через Google Sheets і Telegram
Коли органічний трафік просідає, бізнес рідко дізнається про це в ту саму хвилину. Частіше сценарій інший: кілька днів падають кліки по ключовій сторінці, ще через тижде…